爬虫抓抖音某个人的所有评论(爬虫抓抖音某个人的所有评论犯法吗)
本文爬取一共六个平台,十个爬虫案例,如果只对个别案例感兴趣的可以根据:芒果TV、腾讯视频、B站、爱奇艺、知乎、微博这一顺序进行拉取观看。完整的实战源码已在文中,我们废话不多说,下面开始操作!
芒果TV本文以爬取电影《悬崖之上》为例,讲解如何爬取芒果TV视频的弹幕和评论!
网页地址:
微博评论是动态加载的,进入浏览器的开发者工具后,在网页上向下拉取会得到我们需要的数据包:
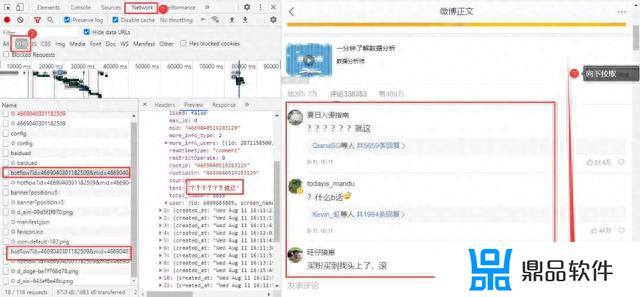
得到真实url:
https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id=3698934781006193&max_id_type=0
两条url区别很明显,首条url是没有参数max_id的。第二条开始max_id才出现,而max_id其实是前一条数据包中的max_id:
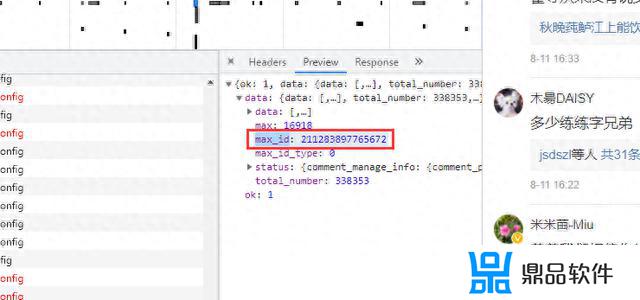
但有个需要注意的是参数max_id_type,它其实也是会变化的,所以我们需要从数据包中获取max_id_type:
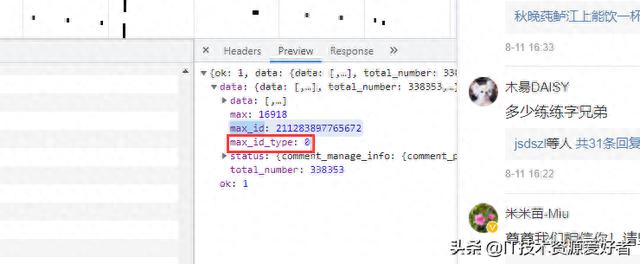
实战代码import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r'<[^>]*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
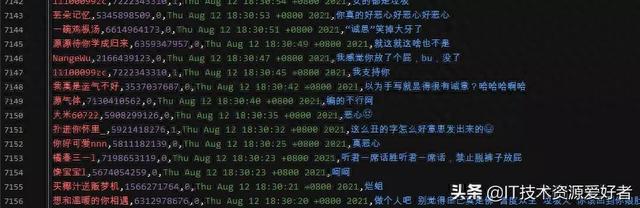
结果展示:
以上便是今天的全部内容了,如果你喜欢今天的内容,希望你能在下方点个赞和在看支持我,谢谢!
以上就是爬虫抓抖音某个人的所有评论的全部内容,希望能够对大家有所帮助。













