抖音的歌曲怎么把人声和伴奏同步(抖音的歌曲怎么把人声和伴奏同步播放)
作者: 鸿洋
原文链接:https://mp.weixin.qq.com/s/EmS5WfBS61qG4CpKW37PyA
就在上个周末,我们见证了一场全球共唱的音乐盛事,One World Together at Home。整场活动汇聚了大量的明星大咖,他们通过线上直播的形式,在家里向全球观众献唱,其中出现了多地艺人同屏献唱的曲目,但这实际上是录播的。数百位来自全球各地的演唱者存在现场设备、网络条件的差异,要实时合唱面临的技术难点极大。
著名音乐电台DJ,SoundArio音乐基金会创始人加菲众就说:
这段话中的延时,为什么”足以抵消全世界顶级音乐人的现场功力。我们来举个例子说明一下。以歌曲《稻香》为例,它的钢琴曲谱是4/4拍,标准乐曲速度为80拍/分钟。副歌部分大约每个音乐小节唱8到12个字,且主要以八分音符和十六分音符组成,基本上每个音符对应歌词中的一个字。粗略计算的话,大约200 - 300ms左右唱出一个字。
不考虑伴奏的情况下,假设两个合唱者A和B之间的端到端延时为100ms。从声音传输流程上来说:
A先唱,B听到A的歌声。此时产生100ms延时;B在听到A的歌声后开始加入合唱,歌声传到A端。此时又产生100ms延时;那么 A听到B的歌声永远延时200ms。根据之前唱每个字所用时间的计算,听感上会至少慢半个字,是错位的。
如果要考虑伴奏的传输,以及伴奏与歌声的混音,情况将更加复杂。一般端到端延时只要低于150ms,听者是感知不到的。所以唱《稻香》这种速度的歌,延时低于80ms可以合唱。如果唱更快速、歌词更密集的歌,延时要求更低,否则合唱时两人永远也对不准拍子,演唱者的体验也非常糟糕。中国与美国相距1万多公里,光速为30万km/s。光纤传输会有一定损耗,可以按照20万km/s计算,中美之间按15000km物理距离粗略计算,单向延时在75ms左右,无法克服的双向物理延时就有大约150ms。而且,One World Together中的4人合唱场景,涉及到多方协作,情况更加复杂,所以以目前的技术水平,跨超远距离的多方合唱是很难做到的。在One World Together中,我们看到的基本都是录播。不过,不论是录播还是真的实时合唱,给观众带来最好的体验才是最重要的。
在很多社交应用中,都有合唱这一功能,这是如何做到的呢?
我们首先解读一下延时是如何产生的。这个场景下的延时包括两部分:设备端的延时和端到端的延时,我们需要针对不同阶段的延时,来分析如何降低延时。
音频在采集端、播放端的延时
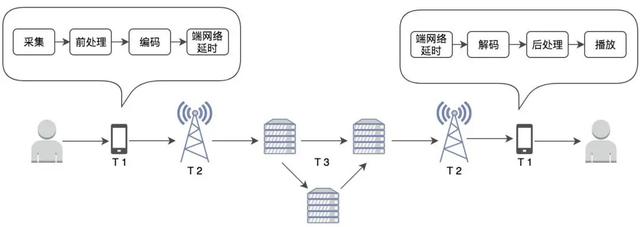
图:音视频传输流程流程
在这里,音频=歌声,或音频=歌声+伴奏。
设备端上的延时包括采集端的采集、前处理、编码,播放端的接收、解码、后处理过程产生的延时,以及两端在编码后和解码前产生端网络延时。端上的延时主要与硬件性能、采用的编解码算法、音视频数据量相关,设备端上的延时可达到 30~200ms,甚至更高。音频在设备端上的延时还可以细分为以下几点:
音频采集延时:采集后的音频首先会经过声卡进行信号转换,声卡本身会产生延时;音频播放延时:这部分延时与播放端设备性能相关;音频处理延时:前后处理,包括 AEC,ANS,AGC 等前后处理算法都会带来算法延时,通常这里的延时就是滤波器阶数;端网络延时:这部分延时主要出现在解码之前的 jitter buffer 内。另外,合唱场景通常会为用户提供各种KTV音效,即人声在编码传输前会增加一步前处理,这还会加大音频在端上的延时。
若想降低音频在端上的延时,就需要针对不同机型进行编解码算法的优化,以降低音频采集、编解码、音频处理带来的延时。端上延时还与设备性能、系统紧密相关,如果歌手中有一方的设备性能较差,也会影响合唱效果。
端到服务器之间的延时
除了端上的延时,音频数据在端到服务器、服务器到服务器之间的传输过程也会产生较大延时,这也是阻碍“实时合唱”功能落地的重要因素。
影响采集端与服务器、服务器与播放端的延时的有以下几个因素:客户端同服务间的物理距离、客户端和服务器的网络运营商、终端网络的网速、负载和网络类型等。如果服务器就近部署在服务区域、服务器与客户端的网络运营商一致时,影响上下行网络延时的主要因素就是终端网络的负载和网络类型。一般来说,无线网络环境下的传输延时波动较大,传输延时通常在 10~100ms不定。而有线宽带网络下,同城的传输延时能较稳定的低至 5ms~10ms。但是在国内有很多中小运营商,以及一些交叉的网络环境、跨国传输,那么延时会更高。
服务器之间的延时
在此我们要要考虑两种情况,第一种,两端都连接着同一个边缘节点,那么作为最优路径,数据直接通过边缘节点进行转发至播放端;第二种,采集端与播放端并不在同一个边缘节点覆盖范围内,那么数据会经由“靠近”采集端的边缘节点传输至主干网络,然后再发送至“靠近”播放端的边缘节点,但这时服务器之间的传输、排队还会产生延时。
在实时合唱的场景中,要解决网络不佳、网络抖动,需要在采集设备端、服务器、播放端增设缓冲策略。一旦触发缓冲策略就会产生延时。如果卡顿情况多,延时会慢慢积累。要解决卡顿、积累延时,就需要优化整个网络状况。
唱歌的人都有一个共同的心理需求,就是希望别人夸自己唱得好听。音质在合唱场景下就显得尤为重要了。而影响实时合唱音质的因素主要包括:音频采样率、码率、延时。
采样率:是每秒从连续信号中提取并组成离散信号的采样个数。采样率越高,音频听起来越接近真实声音。
码率:它是指经过编码(压缩)后的音频数据每秒钟传输所表示的数据量(比特)。码率越高,意味着每秒采样的信息量就越大,对这个采样的描述就越精确,音质越好。
假设网络状态稳定不变,那么采样率越高、码率越高,音质就越好,但是相应单个采样信息量就越大,传输时间可能会相对更长。也就是说,高音质也可能会影响延时。
之前我们提到,因解决方案的不同,“音频”有着不同的含义,这与你的实现逻辑有关。
1.音频=歌声+伴奏
在采集端,我们传输的音频如果是包括歌声与伴奏。那么就意味着是这样的逻辑,如下图。
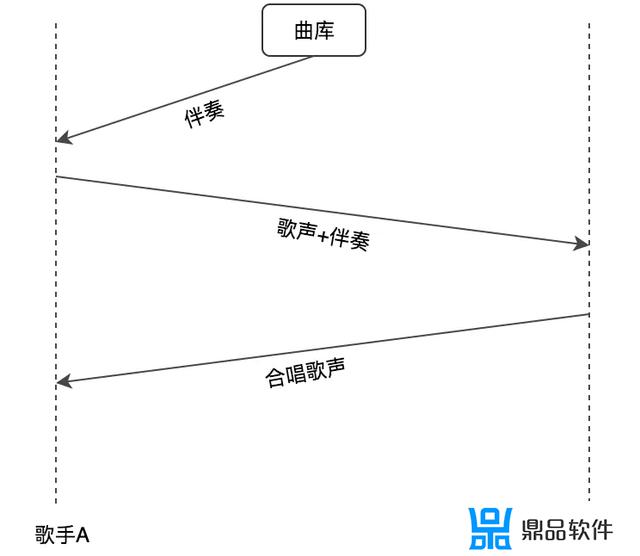
歌手A先获得伴奏;A 将歌声与伴奏在本地混音后传输给 B;B 根据A的音频进行演唱,这时 B 可以听到合唱的效果;B 将合唱后的混音传输给 A,A 就可以听到合唱效果了。
在这种传输方式下,如果要保证 A 能听到合唱效果,会有两段“端到端延时”,即第2、3步产生的。由于B听到的是A的歌声与伴奏,所以该方案能保证 B 的体验。但由于伴奏传输给 B,B 的歌声又需要再传输回到 A,A 听到的伴奏与B的声音其实之间有很大延时。如果按照上文的延时推断,你需要付出更多的努力,才能让端到端的延时降低到歌手A能接受的程度。
2.音频=歌声
在这里,并不是说不要伴奏了。为了解决伴奏、歌声之间的延时问题,我们还有一种方法,就是通过云端将伴奏同时传输给A和B,那么基本可以保证两者能在同一秒听到同一个音符。接下来要解决的就只是歌声的传输了。基本实现逻辑如下,也是我们自己的实现方式:
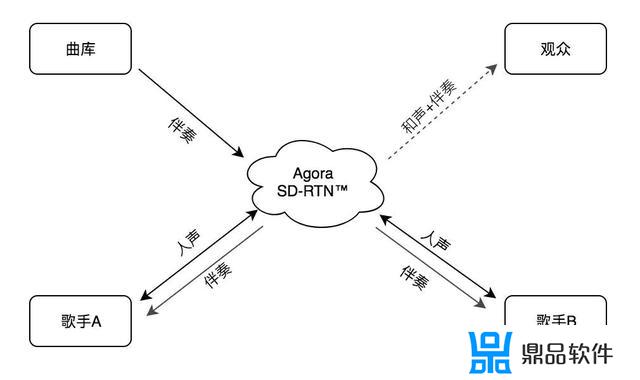
声网从服务器或本地获取合唱伴奏;声网通过 SD-RTN™ 将伴奏,实时同步发送给歌手 A 和 B;歌手 A 和 B 会同时听到伴奏,然后根据伴奏开始自己的演唱;SD-RTN™ 会实时的将A的歌声传给B端,同样,B 的歌声也会被实时的传输到 A 端;歌手A和B都能实时听到伴奏和对方的歌声;同时,观众可以实时听到两个歌手的合唱效果。
这种实现逻辑的好处在于,A、B几乎同时听到伴奏,同时演唱,两者可以实时听到对方的声音。要解决的问题就是降低各自歌声传输到对方的这段端到端延时了。相对来讲,更加简单。
除此之外,其实在线下场景中大家可以看到。很多歌手在唱歌的时候通常都会佩戴耳返,那这个耳返的作用效果在线上实时场景中也是非常关键:
(1)歌手用来监听自己的声音和伴奏,并调节自己音色和情感,这个对延时要求特别高
(2)叠加音效和美声,歌手能听到更极致的音效体验
Agora SDK提供统一接口的低延时K歌耳返功能,通过与手机厂商的深度技术合作,可为K歌、直播类App提供适配不同手机品牌、不同手机机型的耳返应用,我们将传统耳返100-300毫秒的延时降低至50ms以内,结合 Agora 音频整体解决方案,实现超低延时、超低噪声、极致音效的耳返体验。
在github获取我们的合唱Demo,自己动手试试吧
https://github.com/AgoraIO-Usecase/Online-Chorus/
NDK模块开发音视频的开发,往往是比较难的,而这个比较难的技术就是NDK里面的技术。音视频/高清大图片/人工智能/直播/抖音等等这年与用户最紧密,与我们生活最相关的技术一直都在寻找最终的技术落地平台。以前是windows系统,而现在则是移动系统了,移动系统中又是以Android占比绝大部分为前提,所以AndroidNDK技术已经是我们必备技能了。要学习好NDK,其中的关于C/C++,jni,Linux基础都是需要学习的,除此之外,音视频的编解码技术,流媒体协议,ffmpeg这些都是音视频开发必备技能。

以上就是抖音的歌曲怎么把人声和伴奏同步的详细内容,更多抖音的歌曲怎么把人声和伴奏同步播放内容请关注鼎品软件其它相关文章!













