为什么抖音特效露脸会放大(抖音上脸突然放大的特效是什么)
作者&编辑 | 言有三
1. 什么是人脸风格化所谓人脸风格化,就是将人脸头像转换为特定的风格头像,最常见的包括素描肖像风格,卡通形象(动画)风格,油画风格,分别如下图所示:

素描肖像风格的重点在于保持人脸的轮廓和重要五官信息,去掉无关的颜色,纹理等内容,它模仿的是就是素描,相对比较严肃。
卡通形象(动画)风格的重点在于简洁,统一的颜色和纹理风格,对五官进行适当的美化(比如眼睛,鼻子的调整)。
油画风格的重点则在于渲染有艺术感染力的颜色和纹理,对整个内容的改变有时候比较大。
三者的相同之处在于,需要保持人脸的身份信息,即可辨识为本人。
不同之处在于,肖像风格很少会对人脸五官作出大的调整,即不会将小眼睛变为大眼睛,大鼻子变为小鼻子,因为那样就不写实了。而卡通风格的其中一个重点就是要对五官进行调整,因为卡通形象的颜色和纹理比较单一,如果不进行美化,大众脸的五官缺陷很容易被放大。油画风格的差异则比较大,主要在于颜色和纹理风格的调整程度。
下面我们来分析这三类风格的核心技术点。
2. 素描肖像风格从上图肖像风格我们其实可以看出,肖像风格的重点在于线条轮廓的完整性,均匀性,而人脸的形状和五官位置其实不需要作出调整,那么一种最成熟的技术就是边缘检测。
以OpenCV库中具有代表性的两种边缘检测算法为例:
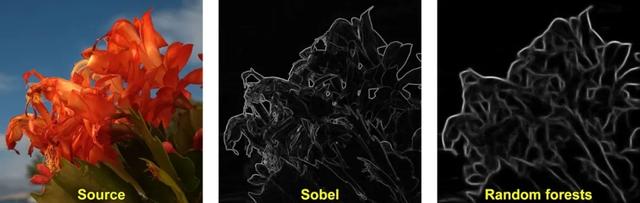
Sobel是一种基于简单的基于梯度信息的方法,Random forests则是基于局部块分类的方法,他们各自有特点。比如Sobel的结果对比度更高,而Random forests的结果更加干净简单。
基于边缘检测作出素描肖像风格,重点就在于参数的调试和后处理,在边缘的召回率和准确率之间取得平衡,代表性的方法可以参考文[2]。这一类方法比较容易受到噪声的影响,如果去细看前面的那张处理图,就能看出一些细节问题。
虽然素描肖像风格本身也可以用最新的一些方法进行生成,比如接下来会介绍的基于图像风格化和图像翻译的方法,但是相对于传统的方法其效果改进并不是非常明显,因此我们就不再做展开解读。
[1] Dollar P, Zitnick C L. Structured Forests for Fast Edge Detection[C]. international conference on computer vision, 2013: 1841-1848.
[2] Winnemoller H, Kyprianidis J E, Olsen S C, et al. Special Section on CANS: XDoG: An eXtended difference-of-Gaussians compendium including advanced image stylization[J]. Computers & Graphics, 2012, 36(6): 740-753.
3. 油画风格说起风格化技术,研究历史其实比较久远,早期的风格迁移方法以Image Analogie[3]为代表,是基于图像块的纹理仿真运算,由于不是基于学习的方法,效果和影响力很有限。真正让大众认识这一门技术的,还是2015年左右的基于卷积神经网络的风格迁移论文[4]的提出,展示了如何将图像进行油画风格化的应用,这是早期基于图像的风格迁移算法。

所谓风格迁移,即将某一幅图像的风格(上图中的小图。也称为风格图)迁移到另一幅图像(上图a,也被称为内容图),得到目标结果图(上图b),目标结果图同时拥有了风格图的风格和内容图的内容
内容是图像的语义信息,指的是图里包含的目标及其位置,它属于图像中较为底层的信息,可以使用灰度值,目标轮廓等进行描述。风格则指代笔触,颜色等信息,是更加抽象和高层的信息。
图像风格可以用数学来描述,其中常用的是格拉姆矩阵(Gram Matrix),它的定义为n维欧氏空间中任意k个向量的内积所组成的矩阵。
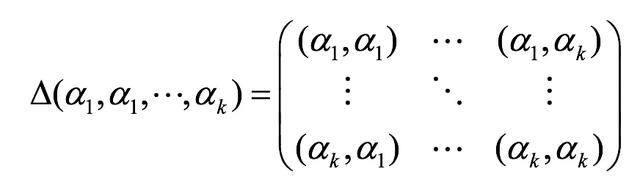
基于图像特征的Gram矩阵计算方法如下。
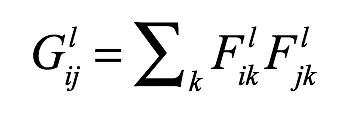
其中Fik_l是向量化后的第l个网络层的特征图i和特征图j的内积,k即向量的长度。
格拉姆矩阵可以看做特征之间的偏心协方差矩阵,即没有减去均值的协方差矩阵,内积之后得到的矩阵的对角线元素包含了不同的特征,而其他元素则包含了不同特征之间的相关信息。因此格拉姆矩阵可以反应整个图像的风格,如果我们要度量两个图像风格的差异,只需比较他们格拉姆矩阵的差异即可。
假设我们有两张图,一张是欲模仿的风格图a,一张是内容图p,想要在不更改内容图p的语义内容的基础上生成带有风格图a的风格的结果图x,就需要同时最小化风格损失和内容损失,即重建风格损失和内容损失。
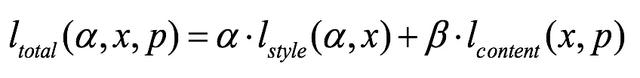
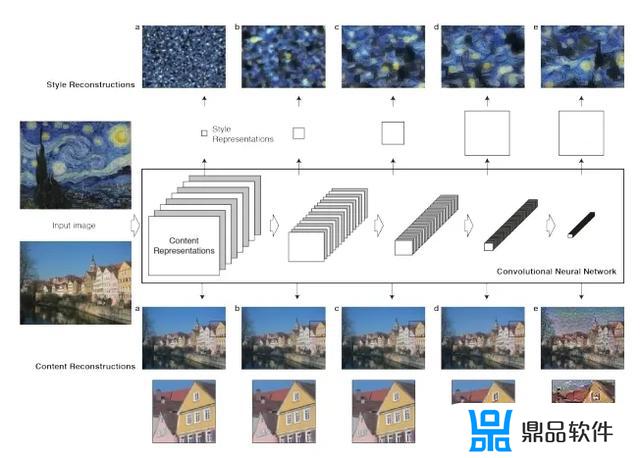
上图包含了两个重建通道。
(1) 内容重建通道。选择某一个抽象级别较高的特征层计算内容损失,它的主要目标是保留图像主体的内容和位置,损失计算如下,使用了特征的欧式距离,和分别是第l层生成图和内容图的特征值。
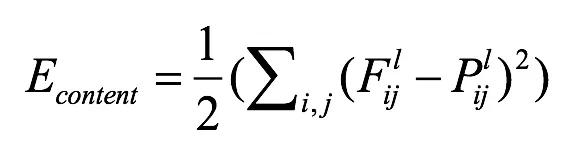
(2) 风格重建通道。与内容重建不同,CNN从底层到高层的每一层都会对损失有贡献,因为风格采用格拉姆矩阵进行表述,所以损失也是基于该矩阵计算,每一层加权相加,第l层的损失定义如下。
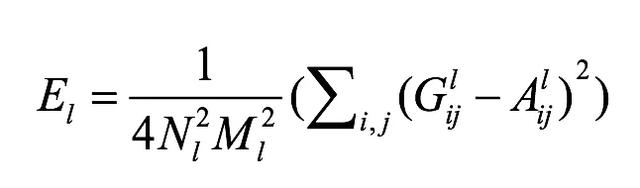
整个的风格损失函数计算则如下:
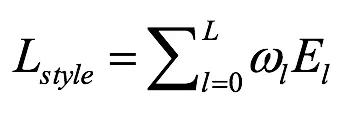
上述的风格迁移算法中内容重建不使用多尺度,是因为内容图本身只需要维持可识别的内容信息,多尺度不仅会增加计算量,还引入噪声,抽象层次较低的低尺度关注了像素的局部信息,可能导致最终渲染的结果不够平滑。风格重建使用多尺度不仅有利于模型的收敛,而且兼顾了局部的纹理结构细节和整体的色彩风格。
上述方法是基于图的风格化方法,非常耗时,当前的主流方法是基于模型的方法,可以实现单一模型进行单种,多种,甚至任意风格的转换,感兴趣的同学可以阅读综述文章[5]进行学习。当然在基于模型的方法中,仍然会借鉴格拉姆矩阵进行风格的表示。
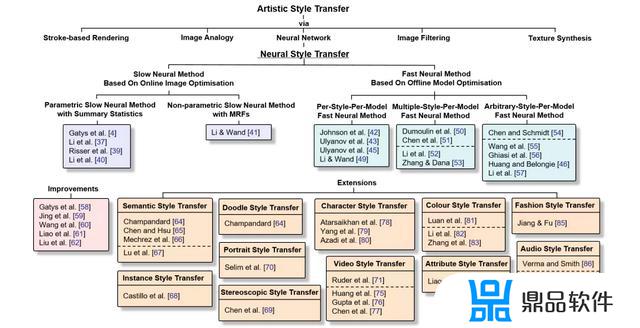
[3] Hertzmann A, Jacobs C E, Oliver N, et al. Image analogies[C]. international conference on computer graphics and interactive techniques, 2001: 327-340.
[4] Gatys L A, Ecker A S, Bethge M, et al. A Neural Algorithm of Artistic Style[J]. arXiv: Computer Vision and Pattern Recognition, 2015.
[5] Jing Y, Yang Y, Feng Z, et al. Neural Style Transfer: A Review[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
4. 动画风格动画风格,这里特指的就是有某种动画作品风格的效果了,以日本的二维动画为代表,最近抖音新增的特效就属于这种,实际效果如下:

上图我分别测试了正面,大角度,以及本身就是动画的图像,效果都还不错。它采取的是对人脸进行风格化处理,对其他区域进行类似的颜色和纹理迁移的方案。
可以看出的是,尽管输入图的颜色纹理有很大差异,但是输出图则非常一一致,这说明其本质是从输入到特定风格的映射,哪怕输入图本身就是动画,也会被映射到特定的风格。
要实现这一类风格的生成,需要对输入图进行风格编码,最适合的技术便是GAN,其中人脸编码方法中StyleGAN[6]是最成功的方法。不过对于人脸动画风格来说,改变的是整体风格,而不是局部细节,所以原理上更为简单一些。
使用GAN进行风格迁移是一个非常大的研究领域,方法很多,我们这里只能对其中最核心的技术进行介绍,以Pix2Pix和CycleGAN为代表,前者需要成对数据进行训练,而后者则不需要,所以CycleGAN[7]才是更加现实的选择。
CycleGAN通过对源域图像进行两步变换:首先尝试将其映射到目标域,然后返回源域得到二次生成图像。从而消除了在目标域中图像配对的要求,这是一个循环的结构,因此称之为CycleGAN,框架示意图如下:
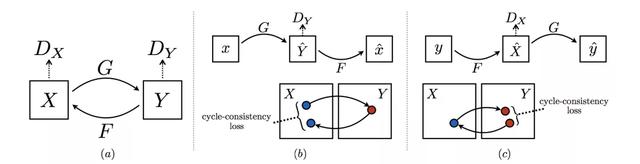
从上图我们可以看出CycleGAN其实就是两个方向相反的单向GAN,它们共享两个生成器,然后各自有一个判别器,加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,CycleGAN加起来总共有四个loss。
X和Y分别表示两个域的图像,可知这里存在两个生成器G和F,分别用于从X到Y的生成和Y到X到生成,包含两个判别器,分别是Dx和Dy。完整的loss如下:
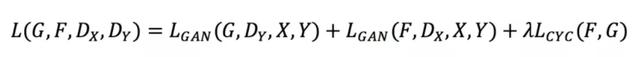
前两项就是普通的loss,Lcyc则是CycleGAN框架的重点。
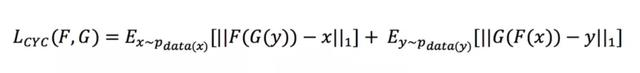
背后的意义就是样本从一个空间转换到另一个空间后,反之还可以转换回来。
直接使用CycleGAN是不可能得到一个工业界的模型,因为CycleGAN确缺少对人脸语义信息的理解,会得到下面这样的效果。

所以需要对其进行改进,让它能够理解语义信息,只处理该处理的区域,保证人脸五官分布的合理,其中有两个方法是比较典型的,都是基于CycleGAN的改进,对人脸进行风格化的主流算法基本无出其右。
一个是使用关键点进行约束的方法[8],通过增加关键点预测任务,来约束输出图像的五官分布。
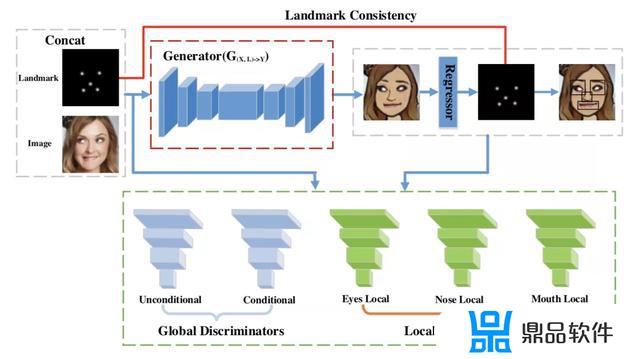
另一个是基于注意力机制的方法[8],使用注意力机制对人脸的有效区域进行学习。
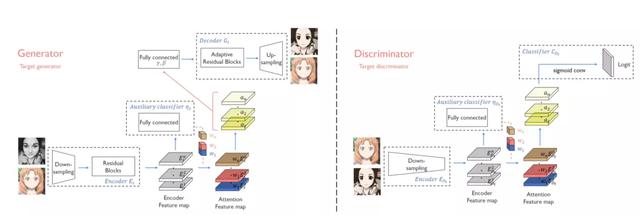
下面是使用文[9]方法处理的结果,可知效果要好很多了,这是一个非常有希望的方法,对数据集进行优化后,有望取得很好的效果。
关于详细的工程解读,我们之前有过文章,大家可以参考。

动画风格化相比于素描和油画,对细节比较敏感,因为使用了特征编码,难点在于人脸的五官分布不能丢失或者错乱,其中人脸图像中的经典难题会对结果造成很大影响,比如光照,姿态等
下图展示了处理失败的案例。

[6] Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 4401-4410.
[7] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[8] Wu R, Gu X, Tao X, et al. Landmark Assisted CycleGAN for Cartoon Face Generation.[J].arXiv: Computer Vision and Pattern Recognition, 2019.
[9] Kim J , Kim M , Kang H , et al. U-GAT-IT: Unsupervised Generative Attentional Networkswith Adaptive Layer-Instance Normalization for Image-to-Image Translation[J]. 2019.
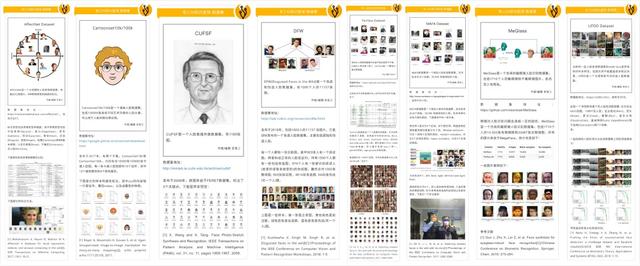
5. 人脸风格化数据集人脸的风格化在娱乐社交领域里有非常广泛的应用,下面我们给大家介绍一些用得上的数据集。
(1) CUFSF
数据集地址:http://mmlab.ie.cuhk.edu.hk/archive/cufsf/。
发布于2009年,这是一个人像素描数据集,原图来自于FERET,有1195张成对的灰色正面肖像图和对应的素描图。
(2) IIIT-CFW1.0
数据集地址:http://cvlab.cse.msu.edu/siw-spoof-in-the-wild-database.html。
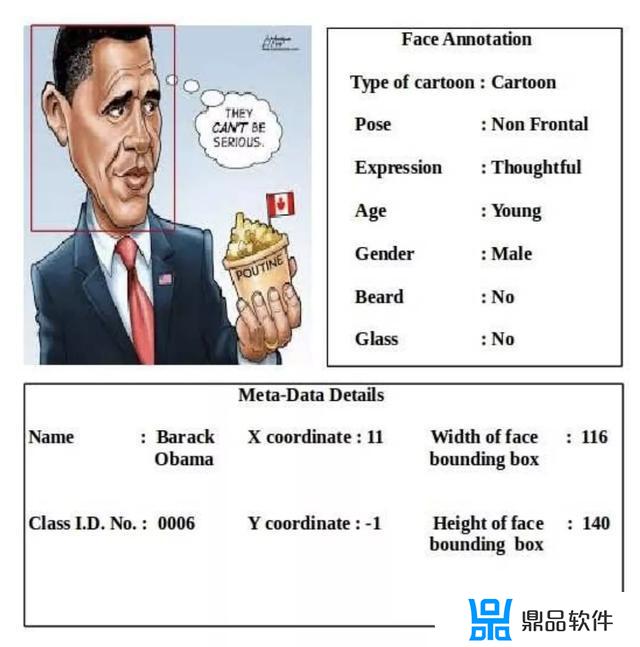
发布于2016年,包含100个名人的8928张卡通图片,同时也附带了1000张真实图。
(3) CartoonSet10/100k
数据集地址:https://google.github.io/cartoonset/download.html。

发布于2017年,有两个子集,CartoonSet10k和CartoonSet100k,分别包含10000和100000张卡通人脸图。每一张卡通人脸图都有16个组件,其中12个面部属性和4个颜色属性。
其中颜色属性来自于一个离散的RGB集合,每一个属性的种类可以低至3种,高达11种。比如chin的长度就包括short、medium、long一共三种,而发型就有111种。所有属性及其集合大小统计如下:
艺术风格总共包括:3种下巴长度(chin_length)、3种眼睛角度(eye_angle)、2种睫毛可见与否属性(eye_lashes)、2种眼睑样式(eye_lid)、14种眉毛形状(eyebrow_shape)、2种眉毛宽度(eyebrow_weight)、7种脸型(face_shape)、15种面部发型(facial_hair,包括光头)、12种眼镜(glasses。包括无眼镜)、111种头部发型(head hair)
颜色风格包括:5种眼虹膜颜色(eye_color)、11种面部皮肤颜色(face_color)、7种眼镜颜色(glasses_color)、10种头发颜色(hair_color)。
比例风格包括:3种眼睛眉毛距离(eye_eyebrow_distance)、3种眼缝大小(eye_slant)、4种眉毛厚度(eyebrow_thickness)、3种眉毛宽度(eyebrow_width)。
所有的元素及其变种都是由同一个艺术家Shiraz Fuman绘制而成,最终得到约250个卡通艺术元素,可以组合成约108种样式。所有的艺术元素都是采用顺序分层的方式方便进行渲染,比如脸型需要依赖于眼睛和眼睛,而发型比较复杂有两个元素,一个在人脸上一层,一个在人脸下一层,总共有8层,头发背景、人脸、头发前景、眼睛、眼睫毛、嘴巴、面部头发、眼镜。
从属性到艺术的映射也是有艺术家确定的,这样任意一个属性的选择都能获得视觉好看的效果,而不至于对不齐,有时候需要一些交互,比如不同脸型的“短胡子”属性的创作。
(4) self2anime
数据集地址:https://github.com/taki0112/UGATIT。

发布于2019年,这是一个漫画人脸数据集,首先使用漫画人脸检测算法对Anime-Planet1上的图片进行了检测,最后留下了女性的人脸图共3500张,其中3400张作为训练,100张作为测试。
(5) Danbooru2019
数据集地址:https://www.gwern.net/Danbooru2019#danbooru2018 。

Danbooru2019是一个动漫人物数据集,拥有超过300百万的图片。有研究者从中选择了一些图片组建了动漫头像数据集,共140000张,图像大小为512*512,如下,地址为http://www.seeprettyface.com/mydataset_page3.html#anime。

其他还有一些比较小和老的数据集,这里就不做过多的介绍,感兴趣的读者可以自行去了解更多。
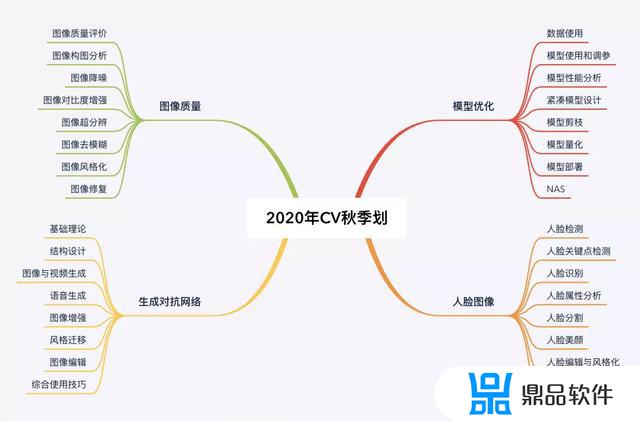
6. 如何学习以上算法在上面我们介绍了用于人脸风格化的核心技术,涉及人脸图像的各种算法,风格迁移算法,生成对抗网络,如果想要长期进行学习,可以参考有三AI秋季划的人脸算组,图像质量组,GAN组,可分别学习相关内容。
详情可以阅读下文介绍:
「通知」如何让你的2020年秋招CV项目经历更加硬核?有三秋季划
如果你对以上人脸数据集感兴趣,在有三AI知识星球的数据集板块中,我们提供了以上数据集的详细解读以及下载方式,有需要的同学可以加入。
而人脸风格化相关的算法,也有诸多介绍。
 总结
总结本次我们给大家介绍了人脸风格化相关核心技术和数据集,人脸图像属于最早被研究的一类图像,也是计算机视觉领域中应用最广泛的一类图像,其中需要使用到几乎所有计算机视觉领域的算法,可以说掌握好人脸领域的各种算法,基本就玩转了计算机视觉领域。

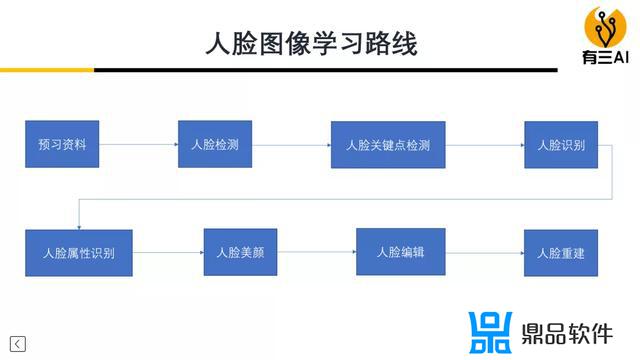
如何学习人脸图像算法
如果你想系统性地学习各类人脸算法并完成相关实战,并需要一个可以长期交流学习,永久有效的平台,可以考虑参加有三AI秋季划-人脸图像算法组,完整的介绍上面有链接,总体的学习路线如下:
以上便是小编为大家带来的为什么抖音特效露脸会放大,希望对大家有所帮助,更多内容请继续关注鼎品软件。













