抖音录音时的换气声怎么消除(抖音录声音怎么弄)
有好长一段时间没有更新文字类的内容了,昨天刚好看到一个网友的问题,就是想要了解如何去除呼吸声。当我看到这个问题的时候,我第一个反应就是,人没了呼吸,怎么行?不过,在实际应用中,不同的情况,对于人声呼吸声的需求是不同的。
录音人声的呼吸声留存不同行业对于人声的处理会有不一样,例如一些语音的播报,或者是店面广告宣传,又或者是火车站机场的AI自动语音广播系统等等,这些属于机械性人声用途的人声,是可以不需要有呼吸声的。
但是,如果是作为节目,歌曲,独白旁白,等等,作为自然人声用途的人声,我们还是建议保留呼吸声,并且通过后期处理,让由于录音距离不正确,或者经过压缩器处理放大的呼吸声,调整为更加自然的音量。
机械性人声用途,去除呼吸声机械性人声用途不需要呼吸声的原因其实主要是,由于这类型的人声在播放的时候,很有可能使用比较简陋的设备,音质可能不会太好,又或者播放的环境比较嘈杂,人的注意力不会放在讲话是否有吸气这个自然点上。再者,吸气声一般都是跟齿音类似,会有很多高频的成分,如果吸气声比较大,在音质差的或者专门突出人声的广播系统音响播放的时候,就会在人声发出之前形成非常刺耳的抽吸声,反而让人觉得听起来极其不舒服。所以,一般为了保证播报的质量,使用机械性的人声时,会把所有呼吸声都去除。如果作为自动语音系统的话就更加不用说了,每一个字都是剪开的,会根据系统内容自动拼接,人人都知道是机器人讲话,就更加不会在意呼吸声了。
那我们第一个先来探讨一下,关于去除人声的常用的方法。
1:剪辑法
首先是,直接剪掉并删除呼吸声,这个是去除呼吸声最佳的办法,因为不会影响到人声本身的质量。只是说,要一个一个地去修剪,是一个非常磨人的功夫,尤其是如果剪辑量非常大的时候,可以说,会直接剪崩溃了。但是不论怎么说,也不影响其最佳方法的宝座。

这里我复制了一行人声,直接对比有呼吸声和没有呼吸声,音频块的区别。上面一行就是呼吸声被剪掉的,下面是保留的。这个没有什么技术含量了,想要剪辑得精准,只需要把波形放大,在呼吸声的两头下刀就可以。这么做的好处是,绝对不会影响人声部分本身的声音。方法简单,直接,干净利落,但是最怕最怕的就是,素材更换,只好重新来了。。
2:噪音门处理
接下来是,如果我们的编辑量非常大的话,真的真的很想偷个懒怎么办,那我们就可以使用噪音门插件来处理。这个方法是可以一次性解决问题,但是又会带来其他的麻烦。
这个方法的第一步是,选用一个方便的噪音门。对于一般的语音处理,我推荐直接使用Waves的C1-gate就可以,操作简单,参数也不多,对于音频本身没有什么染色,基本上不影响音质。当然,如果有条件。不嫌麻烦也可以使用其他,包括很多宿主软件都会自带的GATE的插件或者功能,也可以使用其他更加功能强大的第三方插件,例如 izotope的R7里面的voice-de noice,又或者是slate digital的gate,又或者是fabfilter的G,都是非常好使的工具。
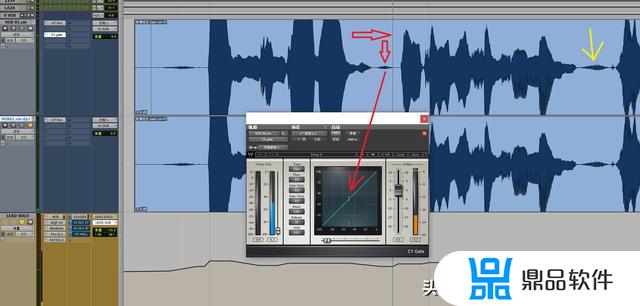
第二步是,我们要知道怎么使用这个噪音门。我们打开噪音门以后,可以播放一下你的素材,尤其是要关注呼吸声的音量,在图中的箭头最终在矩阵中的小白线,就是我们呼吸声的音量大小,图中显示的大概是“-50db”左右。当然,实际操作的话,我建议检测所有素材里面,呼吸声最大的那个(上图黄色箭头所指示的那个),这样才能有效去除所有呼吸声。
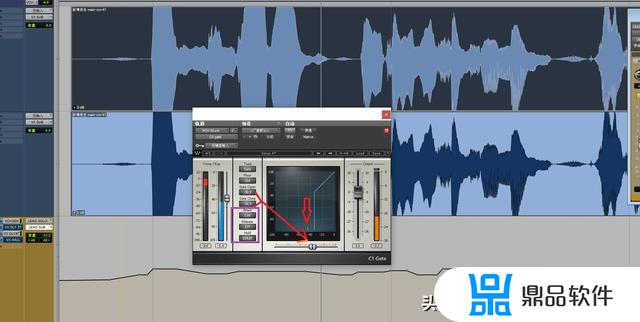
第三步是,开始设置我们的门限的所有参数。这个事情说着复杂,其实做起来也就是几秒钟的事情。我们得到了呼吸声的音量数值以后,只需要将“Gate open”以及“Gate close”这个两个参数,拉到比 -50db 高的位置即可。例如图中,我拉到了“-36.9”,或者手动拉矩阵下方的游标,这个游标跟参数是联动的。
接下来是,我们要设置“attack”这个参数,这个是当检测到的音量大于“-36.9db”时,噪音门打开,让声音播放出来所需要的时间,单位是“ms,毫秒”,我现在设置的是“2.00 ms”就是 千分之2秒。设置这么短的时间的目的就是,只要有人声,就立马开门让声音能播放出来。
然后是,“Release”,这个参数是,当我们的素材音量小于“-36.9db”的时候,噪音门关上把小于这个音量的声音隔绝,所需要的时间,单位同样是“ms,毫秒”。我设置的是“177 ms”,实际上是可以更长,因为人说话是可能会有尾音,而很多时候尾音的音量可能会小于呼吸声,如果过早的关门,会导致尾音直接断掉,人声尾音就会非常不自然。这个参数,我们是需要根据自己听到的结果判断加多少。
最后就是,“Hold”,这个参数跟“Release”有点类似,他跟噪音门的开关有一些关系,这个参数是噪音门关闭以后,我们允许人声自然衰减尾音的时间,同样是“ms,毫秒”作为单位。设置的数值,一般可以跟“Release”相近,当然,也可以根据实际情况加大减小。这个参数是辅助“Release”,让人声的尾音在噪音门关闭的过程中更加自然。
设置好参数以后,基本上,人声的呼吸声,就都被隔离了。但是最开始的时候,我有说到,这个方法也许会带来麻烦。原因就是,很多时候由于我们想要得到很好的人声低频。或者特别想要那种低沉稳健的播音员声音的时候,会离麦克风非常近去录音,结果导致我们的呼吸声变得很大,甚至跟我们正常的语音一样大,并且高频方面跟我们齿音一样大。那这个时候,呼吸声以及人声没有了音量差,那就不能使用噪音门了,又或者强行使用,结果导致人声被噪音门吃掉了很多的声音。还有一种情况就是,有可能只是几个呼吸声比较大,接近人声,大部分都是有音量差,那这个时候,我们还得挨个检查,还是要费不少功夫。
自然人声用途,保留呼吸声,调节至自然自然人声用途,主要就是针对歌曲演唱,对话旁白,等等,我们听到的自然的人声。这样的人声,在我们一般听觉来说,其实就跟我们现实生活中听到人唱歌讲话是一样的。人本身在发声的时候,就是需要自然呼吸,所以这一类的人声,我们是需要保留呼吸声的。否则,我们在听到素材的时候,会有一种强烈的窒息感,会觉得声音非常难受。
另外一点是,由于上面提到的一些录音的问题,导致呼吸声过大,或者由于经过压缩器的工作,导致呼吸声被放大,这样的听感,实际上也会让我们非常的难受。原因是,我们一般听对方唱歌讲话,即便是面对面,都是有距离的,而这种距离是不会让我们听到很大声的呼吸声,而是近乎于听不到,但是没有的话又不自然。如果呼吸声太大,我们听起来就会觉得是对方发声的时候,完全在贴在我们耳边一样,会有种过于贴脸的感觉,也是相当难受,而且每唱一句说一句,都会“嘶,呵,哈”地抽一口,讲真,,,,受不了。
那么下面我们来了解一下,如何得到自然的人声呼吸
1:剪辑法
首先,最直接了当的,同样还是剪辑的手法。跟上面的“去除”不同的就是,我们剪开呼吸声不是为了删掉,而是为了能够单独去调整呼吸声的音量。
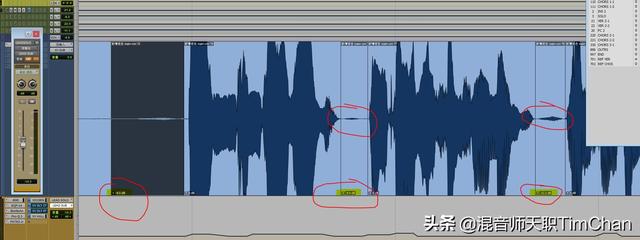
正如图中所示,其实大部分的音频宿主软件都是可以独立调整每个音频块的音量的,那么在剪开呼吸声以后,我们就可以直接拉动音频块的音量调整的功能(包括可能是:滑块,游标,推子,数值 等等)直接调整呼吸声的音量。而且一般音量调整的同时,波形也会直接反映出音量的大小,我们可以从听觉以及视觉上同时判断要调整到多少比较合适。这个是最直接了当,而且质量最高的做法。当然,最后一定要记得给音频块做 fade in 和 fade out,以免有的宿主由于音频块的断口,产生“click”的杂音。剪辑可以说是非常非常麻烦的做法,素材量大的时候,也是会剪辑崩溃的,但绝对是质量最高的方法之一。
不过,这个方法有个致命的缺点就是,如果制作人方,突然跟你说,要换素材,即便是时间轴完全相同的素材,也会立马废掉你前面所做的所有功夫。我觉得没有比这个更加崩溃的事情了,于是乎,就有了下面这个“改良”的办法。
2:Automation 自动化调整
使用“Automation”,就是我们一般说的,参数自动化,很多一知半解的人就会称其“包络线”。这个方法就是使用我们一般音频宿主软件自带的,能够让参数随着时间变化而自动调整的重要功能来实现的。
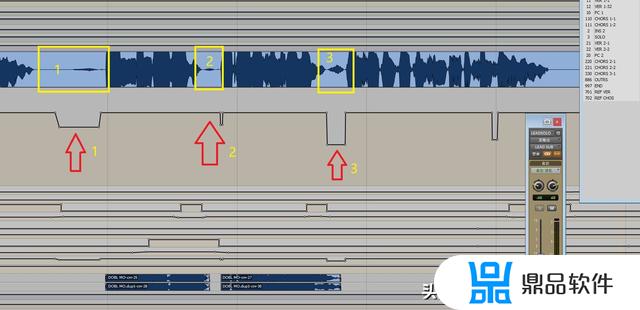
首先,我们只要打开需要处理的素材的音量曲线,(这个就不详细讲了,每个宿主不同,不懂的话,就好好学习自己使用的宿主的基础操作吧)然后,针对每一个呼吸声设置把音量拉下来即可。跟剪辑的原理其实差不多,只是,我们剪辑的是音量曲线。
这个方法,有一个大大的好处就是,如果制作人方要换素材,只要素材的时间轴是对应的,那么我们就不需要再重新剪辑了。只要直接把素材对应着时间轴替换上去即可,因为音量曲线是会保留在工程中的,这样就可以直接对应到我们原来的所有呼吸口。当然,我们实际上,还是要检查一遍的,可能需要调整个别的地方,但也好过一切从头来。
3:De-breath 呼吸声处理器
接着还是要讲一个懒人办法,就是使用插件处理,暂时没有很多很好的呼吸声处理器。而Waves厂还是给我们提供了一个我暂时找到的唯一一个。不过我要说,机器处理事情,还是偶尔会有bug的。并且,这个插件是会让音频的播放产生延迟,一般需要打开延迟补偿,或者自己调整音频的位置来解决这个问题。
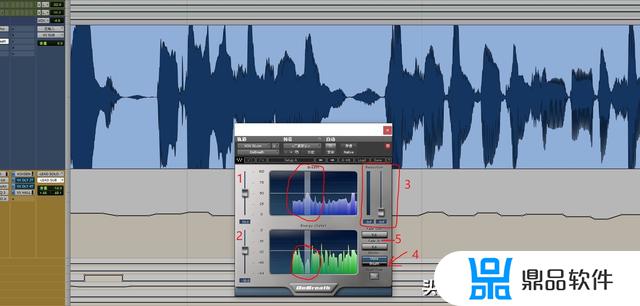
第一步,识别呼吸声,就是图中的“1”这个推子,它对应的是旁边紫色波形窗口中白色的横线,这个是“阈值”。窗口显示的是通过识别一般呼吸声的频响范围得到的波形图,高出来,并且高亮的,一般是呼吸声,这个是插件自动帮我们算出来的。然后我们只要将“1”这个推子往下拉,并且能够基本上触碰到所有呼吸声的一小部分即可。
第二步,再次识别呼吸声,图中“2”号推子,同样是“阈值”,对应的是右边绿色波形窗口的白线,这个是检测全频实际音量的示波器,真实反映我们的呼吸声实际上在音频中的大小,同样是图中高亮的部分。那么这个推子是要拉高的,让阈值线高于被检测出来的所有呼吸声一小段距离即可,不要高太多。
第三步,通过了双重识别以后,我们就锁定了所有的呼吸声,并且自动全部隔离。然后,我们就可以推起“3”号推子,这个是我们想要保留多少呼吸声音量的一个操作。默认是“-Inf”就是无穷小,换句话就是没有呼吸声。推起推子以后,就可以听到呼吸声了,你想给多少音量,随自己喜欢就好。
“4”号功能是可以让我们切换单听所有呼吸声,以及所有素材声音的监听选择。“5”是呼吸声“来和走”的“attack”和“release”,一般保持“5 ms”比较适合。
使用插件处理呢,就跟上面使用噪音门一样,会有误判的情况出现的,很多时候会跟“zhi chi shi”一类的齿音搞混,因为它们的频响范围,和音量很多时候有可能是一样的,那么这种时候,插件就一定会误判。所以,即使用了插件,也还是要从头到尾播放去检查,如果碰到这种情况,就只能通过剪辑的方法,单独把那些“zhi chi shi”的人声的部分调小,来避开插件的检测了。总之,使用插件不是最优的办法,而且实际上,插件会有比较长的运算延迟,在监听的时候会不太方便。
简单总结实际上,呼吸声的处理,就一直是人声后期的一个烦心事儿,而且也没有比通过剪辑更加直接了当的办法了。这个一直就是个费时间费工夫的事儿,但是如果处理好了,得到的结果是非常非常让人听感舒适的。
我个人觉得,无论如何,越是“想”省事儿,越是省事儿的办法,很多时候反而可能给你带来更多新的麻烦,结果绕来绕去没弄出好结果,工夫还没省。所以啊,,,呼吸声处理都还是要踏踏实实下剪刀最好。
喜欢「音乐杂谈」这个主题的朋友可以关注我的头条号,将会在不定期发表一些音乐理论以外的音乐话题的文章或者是音乐知识的干货 。(此文为混音师天职老师 发布于今日头条的原创文章,转载请告知并注明出处)

以上便是小编为大家带来的抖音录音时的换气声怎么消除,希望对大家有所帮助,更多内容请继续关注鼎品软件。













